chatgpt识别图像 由ChatGPT谈谈下一代多模态模型的雏形
本文约5800字,建议阅读11分钟
本文浅谈对多模态模型的新的认识。
最近风头正劲,但只能理解文字或多或少限制其才华的发挥。得益于在NLP和CV领域的大放异彩,多模态近几年取得了非常大的进步。但之前的工作大多数局限在几个特定的,比如VQA,ITR,VG等任务上,限制了其应用。
最近, Li大佬挂出了他最新的杰作。让我对多模态模型有了一些新的认识,希望通过本文分享一下我的想法。由于本身水平有限,加上很长时间没有过相关领域的论文了,里面大部分的思考可能都是闭门造车,所以不可避免有很多错误,欢迎大家指正讨论。

,BLIP, 都是 Li [1]大佬的杰作,给了我很大的启发。去掉了笨重的,BLIP统一了理解与生成,再次刷新了我的认知,感谢大佬!
TL,DR
先一言以蔽之:
实现了开放性的多模态内容理解与生成,让我们有了更多的想象空间;
从新的视角去看待图文模态,引入了LLM模型。CV模型是传感器,负责感知,LLM模型是处理器,负责处理;
相对友好的计算资源,比起动辄几百张卡的大模型chatgpt识别图像,BLIP 2 最大的模型也不过16张A100 40G;
传统图文任务上性能爆表。
从泰坦尼克号说起
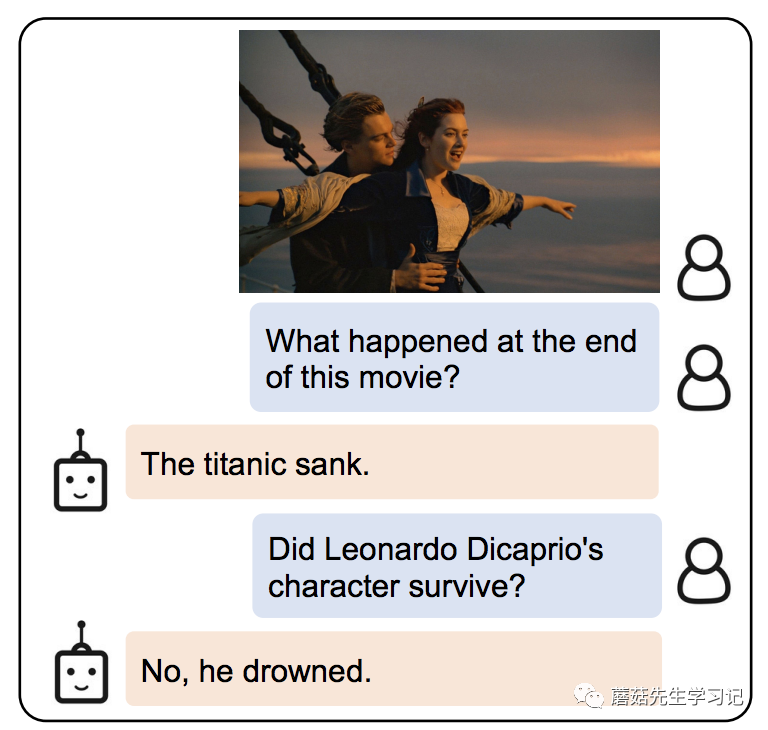
开始前介绍论文前我们先来讨论下,实现图片中的问答,需要什么能力呢?
图片里发生了什么:一位男士在船头搂着一位女士。(感知-CV模型的能力)
问题问的什么:电影的结尾是什么?(感知-NLP模型的能力)
图片和电影有什么关系:这是泰坦尼克号里的经典镜头。(对齐融合-多模态模型的能力)
电影的结尾是什么:泰坦尼克号沉没了。(推理-LLM模型的能力)
对不同模型扮演角色的理解
从上面的问题可以看出,为了解决这个问题,需要几个模型配合一下。其实自从多模态模型 (特别是图文多模态模型) 出现,模态之间怎么配合就是个问题。

19年、20年的时候,和采用了-Text对来提升模型对图片的理解能力。的引入,不可避免的需要一个笨重的检测器,去检测各种框,使得图像模态显得比较笨重。而且检测器模型不可避免的会存在漏检的问题,可以参考后来Open-一些工作,比如ViLD。这一阶段,显然对图像的理解是多模态的重头戏,文本更多是辅助图像任务的理解。
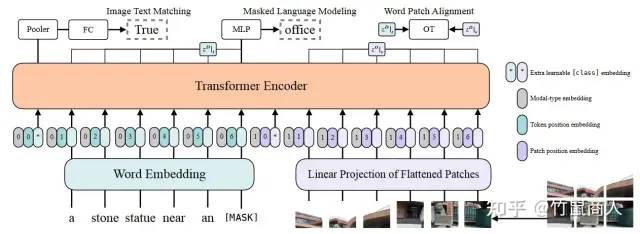
到了21年、22年,去掉检测器成了主流,ViLT,,VLMo,BLIP 等等都抛弃了检测器,彻底摆脱了CNN网络的舒服,全面拥抱,当然这也得益于本身ViT模型在CV领域的大放光彩,让两个模态的有机融合成为了可能。在这一阶段,文本模态感觉已经可以和图像模态平起平坐了。从在各项具体下游任务(VQA、VG、ITR)的实际表现上来说,已经比较令人满意了。但总感觉差点味道,就是复杂推理。比如VQA上的问题,大多数是简单的逻辑计算或识别,感觉还不够智能。
那么如何实现更加复杂的推理呢?众所周知,NLP领域一直领先于CV领域的发展。得益于更丰富的语料库,NLP领域的已经拥有了一些具有初步推理能力模型的研究,特别是LLM大模型的出现。(今天谷歌刚刚发布了22B的ViT,而在NLP领域这个规模的模型应该已经不算新闻了。)我对于LLM能力有多强的理解,其实也是之后才有明确的感知。
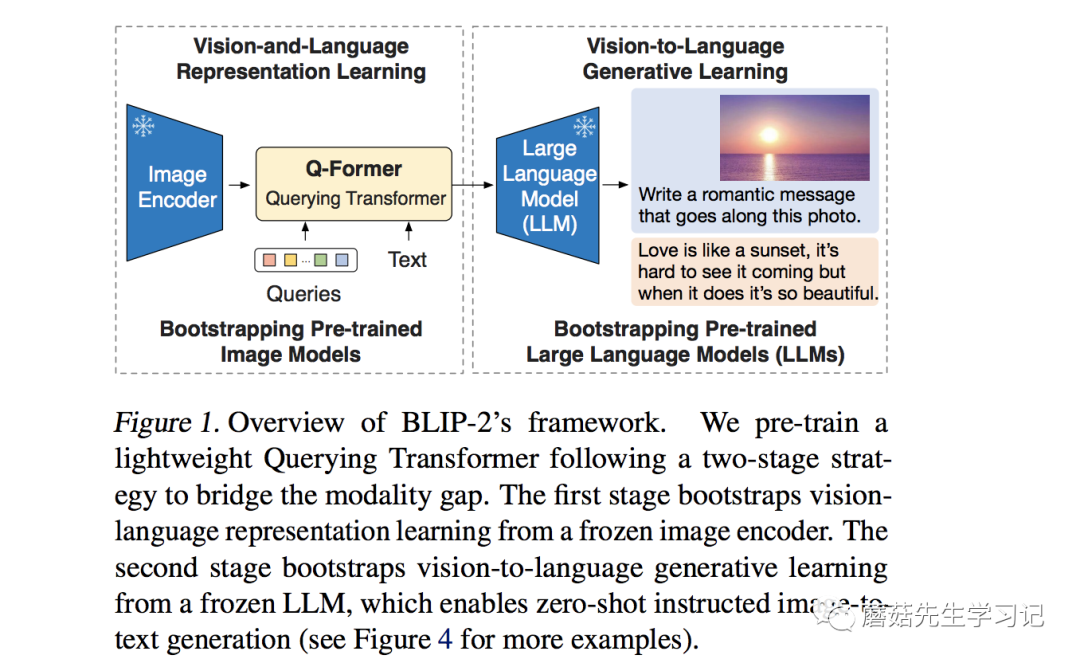
23年1月,出来了,引入了LLM。从图像上看,大概由这么几个部分组成,图像()输入了图像编码器( ),得到的结果与文本(Text)在 Q-(BERT初始化)里进行融合,最后送入 LLM模型。我是学自动化出身的,从自动化的角度看看。
之前的模型大多都关注在了传感器和融合算法的设计上chatgpt识别图像,但忽略了处理器的重要作用。BERT模型虽然能理解文本,但却没有世界观的概念,没有庞大的背景知识库,只能作一个传感器。只有LLM模型,才能实现这一角色chatgpt识别图像,统一起各个模态的信号,从一个宏观的角度去看待这个问题。这里引用一段原文中的话。
by LLMs (e.g. OPT ( et al., 2022), ( et al., 2022)), BLIP-2 can be to zero-shot -to-text that , such as , , etc.
目前看,或许LLM就是下一代多模态模型的关键一环。
言归正传,我们开始介绍论文。
如何统一多模态的表征
LLM本质上是个语言模型,自然无法直接接受其他模态的信息。所以如何把各个模态的信息,统一到LLM能理解的特征空间,就是第一步要解决的问题。为此,作者提出了Q-。
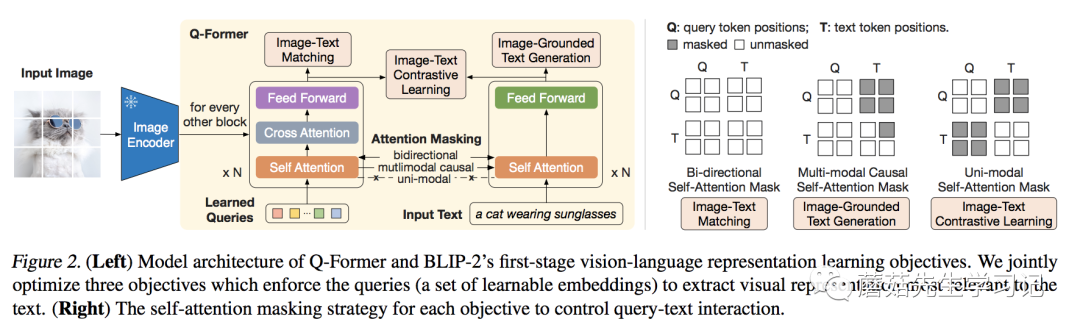
为了融合特征,那架构是最合适不过的了。熟悉或者BLIP的同学或许发现,Q-的结构和其实很像,如果看代码[3]的话,可以发现就是在基础上改的。
相较于,最大的不同,就是 的引入。可以看到这些通过-与图像的特征交互,通过Self-与文本的特征交互。这样做的好处有两个:(1) 这些是基于两种模态信息得到的;(2) 无论多大的视觉,最后都是长度的特征输出,大大降低了计算量。比如在实际实验中,ViT-L/14的模型的输出的特征是的大小,最后也是的特征。
这里其实有点疑问,也欢迎大家讨论。论文里是这样讲的:
This with our pre- into the to that is most to the text.
作者通过Q-强制让提取文本相关的特征,但如果在推理时没有文本先验,那什么样的特征算是相关的呢?
针对Q-的三个训练任务分别是 -Text (ITC),- Text (ITG),-Text (ITM)。其中 ITC 和 ITM 任务,与中的实现类似,只不过图像特征改为了的特征,具体可以参考代码实现(ITC[5]和ITM[6])。这里比较特别的是ITG任务,与中的MLM不同,这里改成了生成整句Text的任务,类似,具体代码实现ITG[7]。实际上,这几个任务都是以特征和文本特征作为输入得到的,只不过有不同的Mask组合,具体可以参考上图中的右图。
第一阶段,对于模型的训练,就是由以上三个任务组成,通过这几个任务,实现了对于特征的提取与融合。但现在模型还没见过LLM。我们现在用传感器完成了数据的提取与融合,下一步,我们得把数据转换成处理器能识别的格式。
变成LLM认识的样子
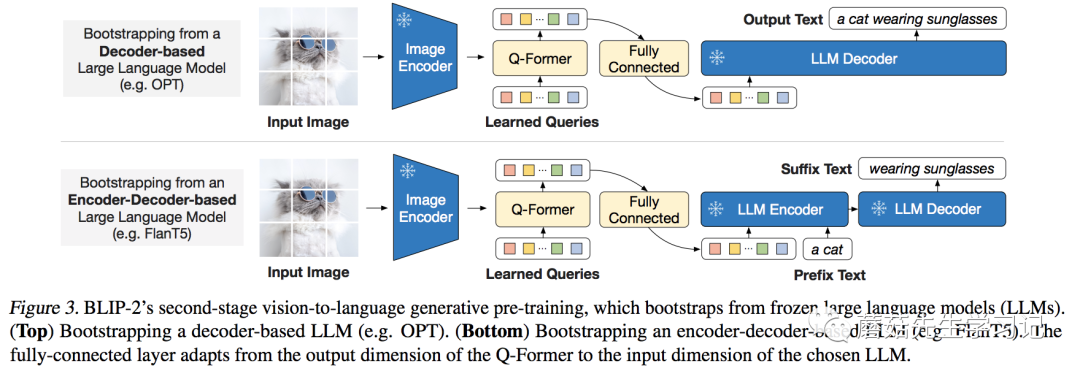
通过第一阶段的训练,已经浓缩了图片的精华,现在要做的,就是把变成LLM认识的样子。
为什么不让LLM认识,而让变成LLM认识呢?这里的原因有两:(1)LLM模型的训练代价有点大;(2)从 的观点来看,目前多模态的数据量不足以保证LLM训练的更好,反而可能会让其丧失泛化性。如果不能让模型适应任务,那就让任务来适应模型。
这里作者针对两类不同LLM设计了不同的任务:
类型的LLM(如OPT):以做输入,文本做目标;
-类型的LLM(如):以和一句话的前半段做输入,以后半段做目标;
为了适合各模型不同的维度,作者引入了一个FC层做维度变换。
至此,模型两阶段的训练方法就介绍完了。
训练细节
作为图文预训练的工作,工程问题往往是关键。的训练过程主要由以下几个值得关注的点:
训练数据方面:包含常见的 COCO,VG,SBU,CC3M, 以及 115M的中的图片。采用了BLIP中的方法来训练数据。
CV模型:选择了CLIP的ViT-L/14和ViT-G/14,特别的是,作者采用倒数第二层的特征作为输出。
LLM模型:选择了OPT和的一些不同规模的模型。
训练时,CV模型和LLM都是冻结的状态,并且参数都转为了FP16。这使得模型的计算量大幅度降低。主要训练的基于BERT-base初始化的Q-只有188M的参数量。
最大的模型,ViT-G/14和-XXL,只需要16卡A100 40G,训练6+3天就可以完成。
所有的图片都被缩放到的大小。
实验部分
作者首先用了整整一页的篇幅,为我们展示了的 zero-shot -to-text 能力。这里暂且按下不表,到后面一起讨论。我们先看看在传统的一些图文任务上的效果。
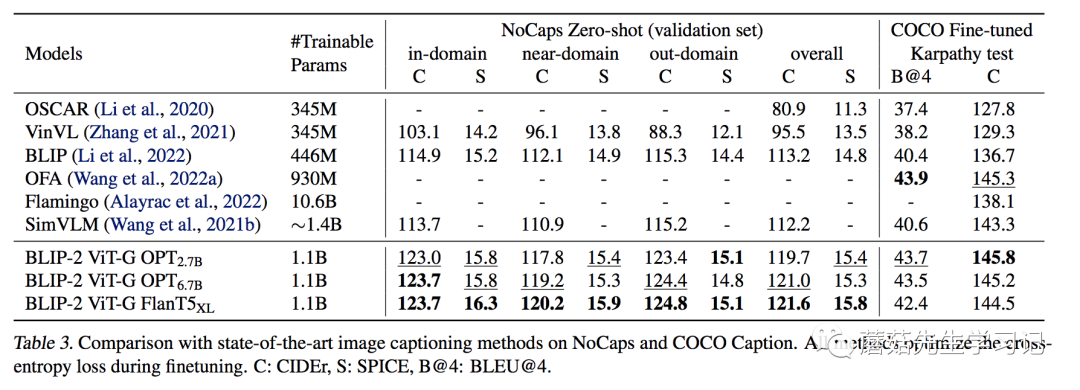
作者用图片配合文字 “a of”作为模型的输入。训练过程中冻结LLM,训练Q-和CV模型。可以看到,在域内数据集(COCO)上,其表现并没有非常亮眼,但在域外数据集上,显示出了强大的泛化能力,相较之前的模型有明显的提升。
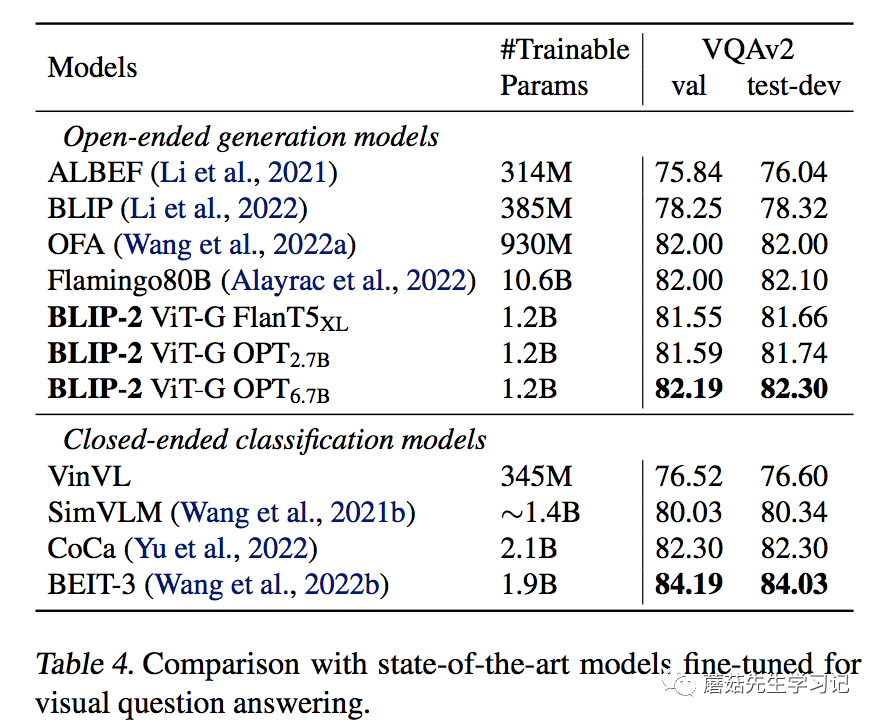
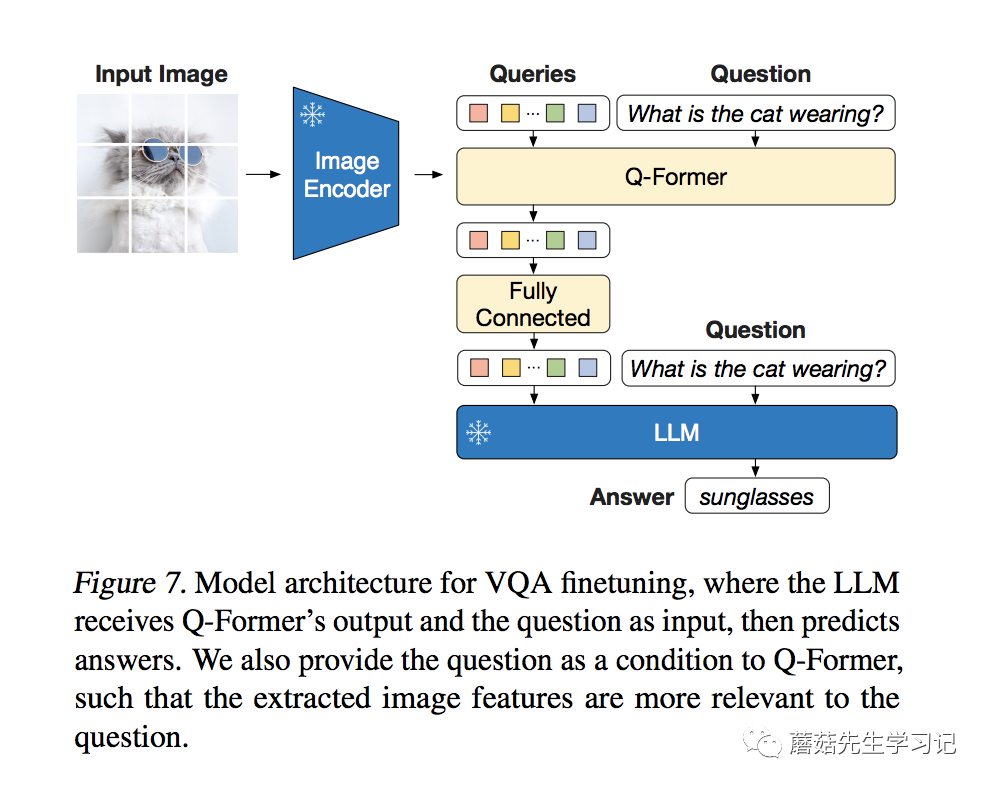
训练的参数和IC任务一致,主要是Q-和ViT。不同的是,Q-和LLM都有作为文本输入。Q-的文本输入,保证了提取到的特征更加的精炼。
-Text
ITR任务,作者只采用了第一阶段的Q-和ViT来做,没有引入LLM。具体的做法与类似,先通过ITC任务算出点积相似度,再取Topk的匹配对,作ITM任务,得到最后的 。上再次刷新了SOTA,特别是I2T,基本饱和了。
Zero-shot -to-Text
我觉得这个能力才是最亮眼的地方。文章中是这样说的:
of zero-shot -to-text a BLIP-2 w/ ViT-G and , it wide of , , , , -to-text , etc.
首先我们来看看对信息的检索能力,下面几个例子都是对图片中物体的背景知识提问,可以看到,模型都给出了相应的答案。这里体现的实际上是LLM强大的背景知识库。图中有什么(ViT)+问的是什么(Q-,LLM)+找答案(LLM)。

下面的几个问题,都是要求模型对图片的内容进行进一步的推理。比如图二,需要建立对男人惊讶和鸡之间的因果联系。
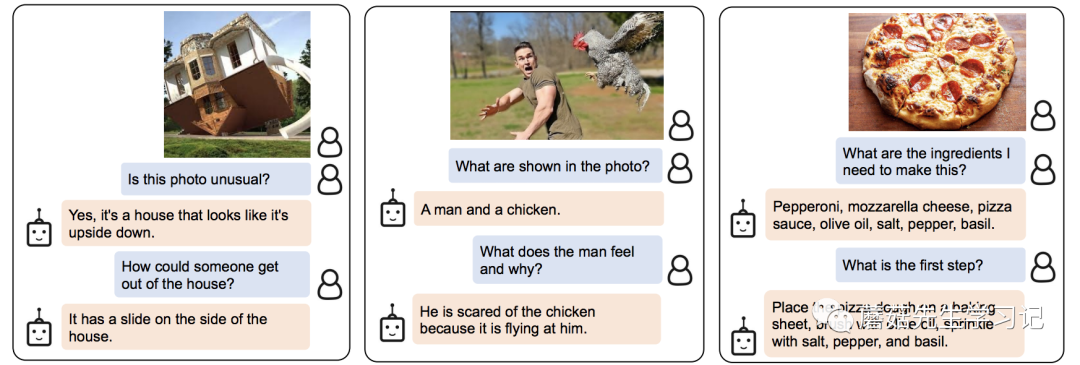
最后的几个问题是开放性的生成问题。需要模型有一定的长文本生成能力。
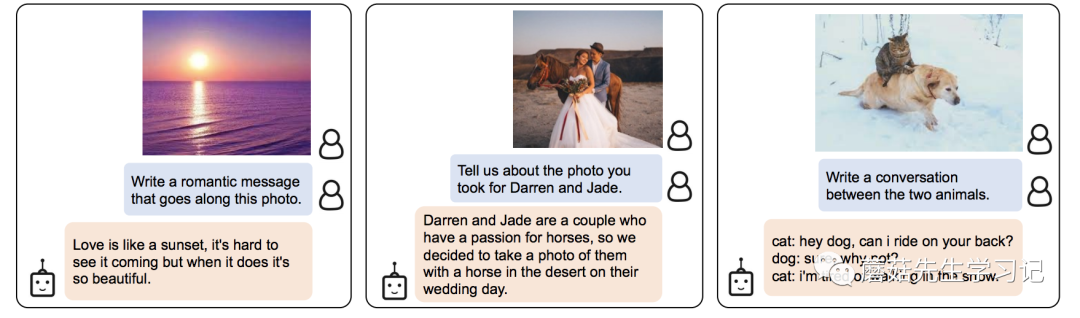
为了进一步探索模型的效果,我也自己测试了一些Demo,这里采用的是ViT-G和的模型组合, Face 上提供的CKPT加起来有50G左右了,作为一个平时接触CV多一点的人来看,是想当炸裂的,一般我模型的CKPT和最后那个零头差不多。
先介绍一下测试的输入格式,这里主要参考[8]
我测试了如下形式的输入样例,其中比较特别的是 ,这里除了图片中的信息,我还会给出一段文本中的信息,希望模型通过综合两个模态的信息给出答案。
下面是一些测试样例以及有趣的发现。粗体为模型的输出结果。
样例: 380

首先,我们问几个简单的问题
Q: What type of is this?
A: a a380
Q: What are the of this type of ?
A: the a380 is the .
可以看到基本给出了正确的回答,但当我询问飞机载客量时,模型确依然给出了380,推测可能是这个飞机和380这个数字的联系比较紧密。
Q: How many can this ?
A: 380
于是,同样的问题,我们给出一点文字上的提示,这里摘取了一段Wiki上的介绍送入模型。
C: The A380 is a wide-body that was and by . It is the 's and only full- -deck jet . in 1988, and the was in 1990 to the of the 747 in the long-haul . The full- -deck has a for 525 , with a for 853 .
Q: How many can the in this ?
A: 853
这时,我们可以看到,模型成功的给出了回答。也就是说,模型有联合两个模态信息联合推理的能力。如果我们使点坏呢,比如给出错误的。
C: The A350 is a long-, wide-body twin- jet and by .
Q: What type of is this ?
A: a350
可以看到,模型输出了错误的答案。可能由于本身LLM对文字更加关注,而且的概念可能对他来说并不熟悉,在他看来,32个只不过是带信息的Word 。
样例:交通标志

在这个样例中,我们直接让模型自己生成个问题。
Q: Give me the .
A: What is the on the road?
接着,我们问问看,模型自己知道答案么?
Q: What is the on the road?
A: 40 mph.
可以看到,模型准确地给出了限速。接着我们让他做一些简单逻辑判断。
Q: Can I 70 mph here?
A: No.
Q: Can I 30 mph here?
A: Yes.
模型竟然都能够正确的给出答案。最后,来个OCR的任务,让模型输出牌子上写了什么。
Q: What is on this sign?
A: 40.
模型同样也给出了正确的答案。可以看到,模型对于逻辑判断和图片中文字的识别,都有一定的基础。
样例:表格

这里先用文章中自己的表格做测试。
Q: What is the name of the ?
A: a of the mri and ct .
Emmm,属于是自家人不认自家人了。问问他认识自己不?
Q: Do you know ?
A: is a that in is by the gene.
好吧,不认识。接着又有一些问题,模型的回答也不是很好。
Q: in the best?
A: dcm vs dcm vs dcm vs dcm vs dcm vs dcm.
Q: How many does have?
A: has a of ten .
原因的话,其实比较好理解,表格的图片相对于自然图像的Gap较大,模型本身可能缺乏相应的训练数据;其次,虽然32的使得信息变得精炼,但也使得模型的表达能力有了瓶颈,加上的大小,这种小文字的识别其实是比较困难的。我们看下个例子。
样例:图表1
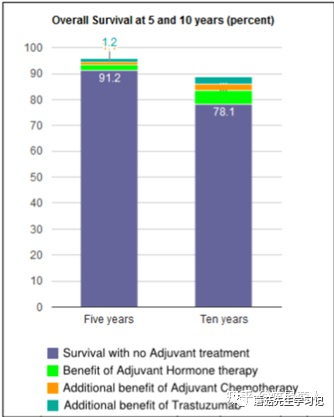
我们让模型自己问个问题。
Q: Give me the
A: What is the of for with no ?
可以看到,模型提问的大致方向是可以的,比如存活率。但是图表中的 却被识别成了 。这说明,模型有一定的OCR能力,但不多。尤其是对于这种比较小又不常见的文字,很容易识别错误。
样例:图表2
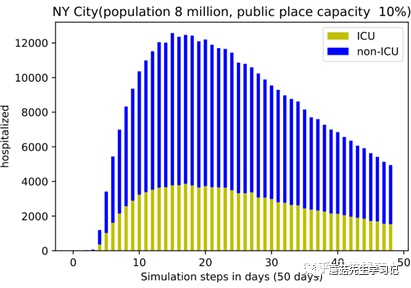
同样,先让模型自己问个问题。
C: : Fig. 3. The and ICU fi from our .
Q: Give me the
A: What is the of the city?
自问自答一下。
C: : Fig. 3. The and ICU fi from our .
Q: What is the of the city?
A: NYC 8 .
从这里不难看出,模型其实对于常见的单词,即使图片比较小也能够很好地识别到。最后来个最难的。
Q: On day 20, how many were ?
A: 200, 000.
这个问题的要求其实挺高,需要模型根据坐标去推断数值,不出意外的回答错误了。
首先,不可否认的是,这篇工作确实让我们的想象空间更多了,尤其是 Zero-shot -to-Text 的能力,我觉得肯定还有没有发现的潜在能力。但我们从测试样例中也看到,模型还存在一些问题。在文章中,作者也给出了一些Bad Case,比如错误的建立联系,错误的推断依据以及过时的知识库。
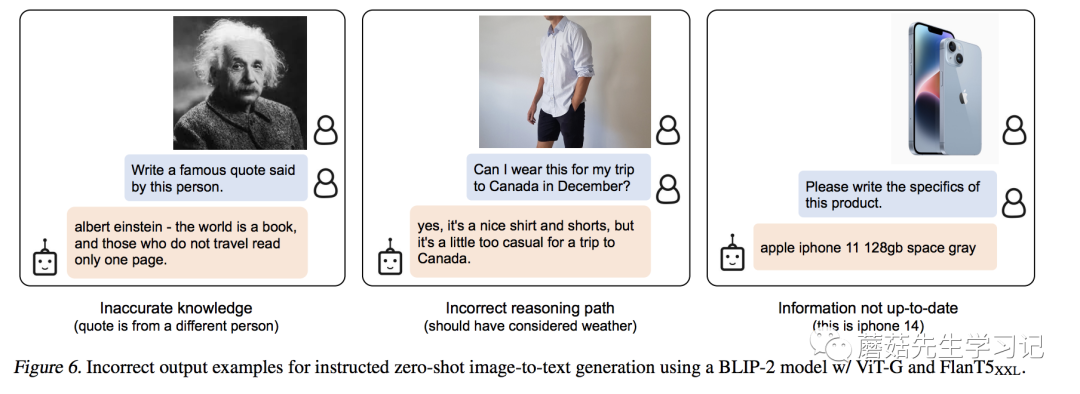
作者在文中对自己模型的不足主要解释为,首先,
, our with BLIP-2do not an VQA when the LLM with in- VQA .We the lack of in- to our , only a -text pair per .
由于图文数据集大多数是一对一的匹配,所以很难让模型建立上下文的联系。
其次,
BLIP-2's -to-text have due to from the LLM, the path, or not up-to-date new .
这个主要是由于LLM模型本身局限决定的。
除了作者提到的几点,我觉得一下几点也是可以探索的:
细粒度的识别,由于图像的信息都浓缩在了32个中,所以能否识别细粒度信息以及图像中重要的位置信息就成了疑问;
更多的任务,强大zero-shot能力,能不能应用在更多的任务上,多模态的类似VG,单模态的类似。
当然从传感器与处理器的角度去看,其他模态(比如)也可以拿个传感器去测,然后送给处理器分析分析hhh
当然,的能力应该还远远没有被挖掘完,等有新的认识了再分享。
参考
[1] Li主页:
/site//
[2] 论文链接:
[3] 代码仓库:
[4] HF上的Demo:
[5] ITC代码:
#L125
[6] ITM代码:
#L160
[7] ITG代码:
#L228
[8] :/-: This I made with the by .
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。